Automated Validation of Trusted Digital Repository Assessment Criteria
Abstract
The RLG/NARA trusted digital repository (TDR) certification checklist defines a set of assessment criteria for preservation environments. The criteria can be mapped into data management policies that define how a digital preservation environment is operated. We explore how the enforcement of these management policies can be automated through their characterization as rules that control preservation services. By integrating a rule-based data management system with the DSpace digital archive system, we expect to demonstrate automated audits of the TDR checklist for a defined set of local policies. The system is sufficiently general that one can also demonstrate the completeness and self-consistency of preservation environments. This is the concept that all required preservation metadata are controlled by management policies, and that for each management policy the required preservation metadata are preserved.
Categories and Subject Descriptors
H.3.4 [Systems and Software]: Distributed systems, D.2.9 [Management]: life cycle, software process models, H.3.6 [Library Automation]: Large text archives
General Terms
Management, Documentation, Verification.
Keywords
Rule-based consistency management, Policy expression
1. INTRODUCTION
The Research Library Group, in collaboration with the National Archives and Records Administration, has published An Audit Checklist for the Certification of Trusted Digital Repositories [TDR] [1]. The checklist defines a set of management policies that are organized into criteria for the functional properties: Organization; Repository Functions, Processes, and Procedures; the Designated Community & the Usability of Information; and Technologies & Technical Infrastructure. While the document does not specify the implementation of the management policies, we can define rules that check the implied assertions. We examine the set of rules and associated state information required to automate the verification of the trusted digital repository. In effect, we attempt to define the set of rules that validate the trustworthiness of a repository.
We extend this result to examine the completeness and self-consistency of preservation environments themselves. If it is possible to define management policies for authenticity and integrity of records [2], one can assert that a preservation environment is complete when preservation attributes exist for each management policy that track the outcome of applying the policy. We can assert that a preservation environment is self-consistent if for each preservation attribute, a management policy has been defined. An unexpected result from this analysis is that the required preservation metadata for completeness and self-consistency are dependent on metadata attributes used to define the entire preservation environment (people, storage systems, management rules, preservation processes, and preservation attributes), and are not simply associated with metadata attributes that identify records. Our approach can be used to implement a provably trustworthy preservation environment.
2. PRESERVATION ENVIRONMENT
One can think of a preservation environment as the set of software that protects records from changes that occur in hardware systems, software systems, and even presentation mechanisms. Preservation environments insulate records from changes that occur in the external world while retaining the ability to display the records and assert authenticity and integrity of the records. For this to be feasible, the preservation environment must manage all of the names needed to identify, discover, and manage records. The preservation environment must also provide mechanisms to guarantee the ability to parse and present digital data, even after the original creation application has become obsolete. A preservation environment should be able to use modern technology to access and display "old" records.
Preservation management policies define the preservation metadata attributes that should be maintained by the preservation environment. The TDR audit checklist describes a set of assessment criteria that the management policies should conserve. A preservation environment is trustworthy when it implements these management policies.
The DSpace digital asset management software [3], in combination with the Storage Resource Broker (SRB) [4] distributed data management software, is an example of a preservation environment. The combined system supports the implementation of a trusted digital repository for long-term preservation. DSpace provides users with a mechanism to define local curation and data management policies, and standard processing steps for the active, ongoing curation of records. The SRB provides management of the digital assets that may be replicated or distributed across multiple storage systems [5]. Together the two systems provide the capabilities needed to define and implement a preservation environment for a variety of archives in customizable curation contexts.
The DSpace/SRB system provides administrative commands that can be issued to support ingestion of records, check assertions about integrity and authenticity of the preserved records, and control the display of records. For very large collections, these administrative tasks become onerous. The ability to automate the application of administrative tasks that implement management policies is essential for building scalable preservation environments.
At the San Diego Supercomputer Center, an integrated Rule-Oriented Data System (iRODS) is under development [6]. The iRODS system expresses management policies as rules that control the execution of preservation micro-services, and manages the outcomes as persistent state information. Each rule is expressed as an [event — condition — (set of actions)] in which the actions are either micro-services or other rules. For each micro-service, a recovery procedure is defined. The state information that is needed to execute a rule is downloaded from the persistent state information repository into a temporary metadata cache. On successful completion, the persistent state information is updated to preserve the outcome of applying the rule.
Typical micro-services include the validation of access controls, the selection of a storage location, the storage of a record, the replication of a record, and the validation of a checksum. A typical rule may invoke multiple micro-services. Thus a rule for the ingestion of a record may invoke each of the micro-services just described. A beta version of the iRODS system was released in December 2006.
The development of the iRODS environment is based on a description of the properties of a preservation environment. In the development of the SRB data grid, three logical namespaces were used to manage the identity of storage resources, records, and persons. Preservation attributes could then be associated as metadata for an entity defined by one of these namespaces. In the iRODS environment, three additional logical namespaces were required to manage the identity of rules, micro-services, and persistent state information (the metadata that describes the results of applying a rule).
In traditional preservation environments, preservation metadata attributes are mapped onto the logical namespaces used to identify records. We shall see that the management of a preservation environment requires preservation metadata attributes that are mapped onto all six logical namespaces: records, storage systems, persons, rules, micro-services, and persistent state information. The preservation environment needs to manage all components of the preservation environment to successfully satisfy assertions required for a trusted digital repository.
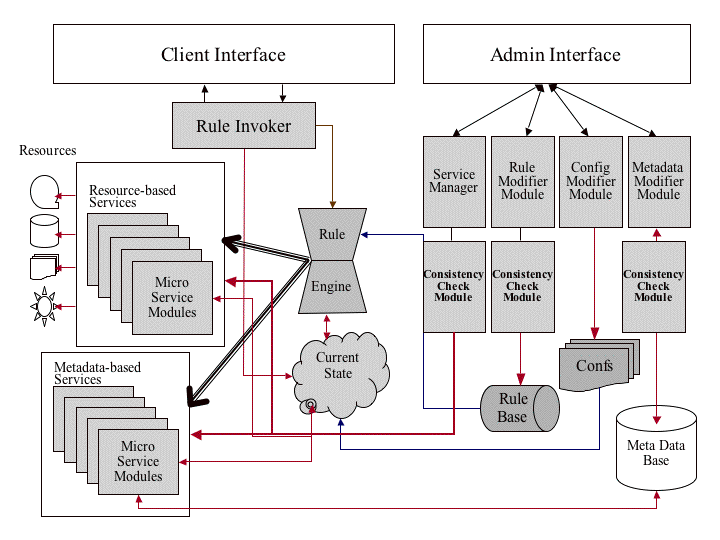
Figure 1. iRODS
rule-based data management system architecture
The architecture of the iRODS system is shown in Figure 1. The shaded components are the extensions applied to data grid technology to implement rule-based data management. The original data grid technology provided a persistent metadata repository (to hold both state information and descriptive metadata), services for the remote manipulation of data and metadata, access methods for administration of the preservation environment, and user access methods. The rule-based environment adds:
- Rule base - this stores the rules that implement the management policies.
- Rule invoker - this loads the rule set needed to manage the interactions of a specified user with a specific record series.
- Rule engine - this executes the rules that express management policies.
- Temporary state information cache - this manages the state information generated on execution of the micro-service set associated with a rule. If recovery procedures are invoked to handle problems with remote storage systems, the metadata updates are made to the temporary state information cache.
- Micro-service consistency check module - when new versions of micro-services are added, the functionality supported by the micro-services is verified for conformance with prior functionality.
- Rule consistency check module - when new versions of rules are added, the persistent state information that is generated is verified for conformance with prior persistent state information.
- Persistent state consistency check module - when new persistent state information is defined, consistency checking is done to ensure no overlap with prior persistent state information.
The six logical namespaces enable a preservation environment to control all properties required to preserve records independently of the choice of hardware and software storage systems. The preservation environment controls the identity of the archivists. The preservation environment controls the file names under which records are stored. The preservation environment manages the access controls defining who is allowed to ingest records, who is allowed to view records, and who is allowed to manage record disposition. The preservation environment can be migrated onto new types of storage systems and new metadata catalogs without having to change any of the namespaces.
The ability to add new versions of rules, micro-services, and persistent state information means that the preservation environment itself can evolve. The management policies used today can be extended to meet the new preservation requirements that become evident as technology evolves.
For this project, DSpace serves as the local curation system in which archivists define local policies for data management and preservation. These policies cover the range of types described in detail in section 4, and are captured in RDF/XML [7] (using the REI RDF ontology) and transmitted to iRODS in an OAIS [8] Dissemination Information Package based of a new METS [9] profile developed for this purpose. The combination of DSpace and iRODS is designed to automate the application of preservation management policies at scale.
3. ASSESSMENT CRITERIA
The TDR audit checklist can be applied to the DSpace/SRB system as implemented by a given organization to determine whether all the management policies are being adequately met to insure long-term preservation of the contents. In this paper we go one step further, and seek to have the DSpace/iRODS system automatically validate the trustworthiness defined by local policy decisions. Our approach is based upon the characterization of each item in the checklist as a rule that must be processed. For each rule, we identify the state information that must be provided to drive the execution of the rule. We then validate the trustworthiness based upon the state information that is generated by the application of the rule. This provides a mechanism to assert how the trusted digital repository is being managed, and also provides the information that is needed to validate the assertion.
In our design process, we discovered many implications within the TDR criteria that impact the ability to describe trustworthiness. We encapsulate these implications in the following observations:
1. The assessment criteria can be mapped to management policies.
2. Implementation of many of the management policies requires mapping to a set of rules that can be automatically evaluated.
3. Management rules require definition of control parameters that define how an assertion is applied, as well as attributes that encapsulate the result of the application of the rule(1).
4. The types of rules that are needed include:
- Specification of assertions (setting flags and descriptive metadata)
- Deferred consistency constraints that may be applied at any time (i.e. a-periodic)
- Periodic rules that execute defined procedures
- Atomic rules applied on each operation (access controls, audit trails)
5. The level of management granularity on which the rules are applied encompasses the enterprise level, the archives level, the collection (record-series) level, and the item level. A specification of the multiple levels of management granularity is needed to understand how to apply the TDR assessment criteria.
6. The rule that is applied at each level of granularity may differ, even though the same assessment criteria are being applied. This is one of the most important observations: that each management policy may require the definition of multiple rules that are applied differently at each level of granularity.
7. Within the DSpace/SRB environment, additional management policies are needed beyond those specified in the TDR document. These include policies related to business case, security architecture, open source software license, user privacy, retention schedule, disposition, destruction of records, withdrawal of records, risk management, protection - data staging; and audit frequency. These should be evaluated for possible inclusion in a future version of the TDR checklist.
8. The actual implementation of the assessment criteria is dependent upon the persistence of the namespaces on which the management policies are applied [10]. The management policies need to apply to persistent identifiers for users, files, storage systems, rules, micro-services, and persistent state information. The persistent identifiers are managed as six separate namespaces. Preservation metadata is then associated with entities identified by each namespaces. Thus preservation properties associated with users (such as access permissions for the archivist who defines preservation properties) are stored as attributes on the user name space. Preservation properties associated with storage systems are stored as attributes on the storage repository name.
9. The trusted preservation repository should implement multiple levels of virtualization to enable migration onto new technology without impacting the ability of the system to meet the assessment criteria. In practice this includes both management of the six persistent namespaces and the management of two levels of mapping between the actions specified in user interfaces and the standard operations for interacting with storage systems (data virtualization). The preservation environment maps from the application level actions to standard micro-services. The micro-services are then mapped to the set of standard operations that can be executed at remote storage systems. A preservation environment also manages the authentication environment (trust virtualization), and the rule execution engine (constraint virtualization) independently of the choice of hardware infrastructure [11].
We also observe that the choice of levels of granularity impacts the types of rules that are needed.
10. The rules used at the enterprise level are typically assertions that define the state information required by rules executed at finer levels of granularity.
11. The deferred consistency constraints are typically applied at the collection level to enforce assertions made on the collection. An example is checking compliance of Submission Information Packages with Service Level Agreement specifications.
12. The periodic rules are applied at the collection (record series) level, and are driven by mandates for periodic validation of integrity. An example would be the validation of integrity every 6 months.
13. The atomic rules are evaluated at the item level on each execution of a related operation. The standard example is the checking of access controls before an operation is performed upon a file.
If additional levels of granularity are defined, such as a record group level, one concern is that additional types of rules may be required. In practice, we expect only these four types of rules. This implies that a rule engine that is capable of executing all four rule types should be able to automate validation of the trustworthiness of a digital repository. The iRODS system has been designed to support the four types of rules that have been identified (specification of assertions, deferred consistency constraints, periodic rules, and atomic rules). Thus the iRODS system should be able to execute the rules that implement the management policies. By creating rules that compare the persistent state information outcomes with the assertions that drive the management policies, iRODS will be able to track whether the management policies are being met. This constitutes automation of the validation of trustworthiness of a digital repository.
Finally, we observe that the mapping of the certification criteria to the management policies planned for the DSpace/iRODS system is not one-to-one. Multiple assessment criteria may apply to a particular repository management policy. We address this issue by explicitly listing each time when the assessment criteria should be applied, and the additional rules that are applied.
4. RULES
To provide a flavor of the assessment, we list some example rule sets for selected TDR criteria. We select an example from each level of granularity, including a case where the same TDR criteria must be evaluated at multiple levels of the data management hierarchy.
The left-most column in tables 1-4 is the management numbering scheme used in the DSpace/SRB policy assessment. The numbering scheme uses 1 for enterprise level, 2 for archives level, 3 for collection level, and 4 for item level. The second number identifies the management policy at that level of granularity. The second column lists the corresponding policy. The third column lists the TDR criteria number that most closely corresponds to the management policy. The 4th column lists the type of rule that is needed. The 5th column lists examples of the state information that are needed for either executing the rule, or for managing the result of the application of the rule. The right-most column provides an explanation of the policy.
Table 1. Enterprise Level Rule Example
|
# |
4. Policy layers / types |
TDR |
Rule or procedure |
State info - result of rule application |
Description |
|
1.5 |
Annual review of planning processes |
|
Set / Update descriptive metadata |
Timestamp of last planning process review |
Annual process to review and adjust business plans |
|
|
|
A4.2 |
Set / Update descriptive metadata |
List of dates of annual review process |
Repository has in place at least annual processes to review and adjust business plans as necessary |
In Table 1, there are two items listed for the policy entitled "Annual review of planning processes." The first row is the criteria as proposed within the DSpace/SRB system. The second row lists the corresponding TDR criteria.
Table 2. Archives Level
|
# |
4. Policy layers / types |
TDR |
Rule or procedure |
State info result of rule application |
Description |
|
2.14 |
Persistent identifiers |
|
Consistency rule - check that handle was created |
List of types of GUID. Lists of locations of handle systems for creating GUIDs |
Management of mapping of identifiers to SIPs. Which type are assigned and to what? Are multiple identifiers for an item supported? |
|
|
|
B2.4 |
Set/update naming specification |
Specification of standard naming convention for physical files |
Repository has and uses a naming convention that can be shown to generate visible, unique identifiers for all AIPs |
|
|
|
B2.5 |
Set/update templates |
Producer-archive submission pipeline for extracting descriptive metadata on ingest; Template based metadata extraction |
If unique identifiers are associated with SIPS before ingest, they are preserved in a way that maintains a persistent association with the resultant AIP. |
In Table 2, two assessment criteria from the TDR checklist should be applied to the management policy for persistent identifiers. The types of rules that are needed include both deferred consistency checking as well as setting of state information needed for rule validation. The persistent identifiers require mapping to the identifier used in the Archival Information Package (AIP) from the identifiers specified in the Submission Information Package (SIP).
In Tables 3 and 4, the same TDR criterion (A5.1) is applied at multiple levels of granularity. Rule A5.1 was applied at both the collection and item level. In addition to managing the service level agreement that specifies the required consistency checks, metadata is also needed to allow changes to the service level agreement to occur. For the item level rule, we also listed the additional TDR criteria that were applied. This indicates that multiple assessment criteria are applicable for a given policy. The validation of the data format requires checking rules related to Service Level Agreements, AIP definitions, allowed transformative migrations, and association of metadata with each file.
Table 3. Collection Level
|
# |
4.Policy layers / types |
TDR |
Rule or procedure |
State info - result of rule application |
Description |
|
3.9 |
Service level agreements for collections |
|
Set / Update flags |
Flag for specification of type of service level agreement |
Maintain a service level agreement for each collection. Specify required descriptive metadata by SIP type. |
|
|
|
A5.1 |
Set / Update descriptive metadata |
Deposit agreement for storage of data specifying access, replicas, consistency checks |
If repository manages, preserves, and/or provides access to digital materials on behalf of another organization, it has and maintains appropriate contracts or deposit agreements. |
Table 4. Item Level
|
# |
4. Policy layers / types |
TDR |
Rule or Procedure |
State info - result of rule application |
Description |
|
4.2 |
Format |
|
Periodic rule - check consistency with required formats |
List of supported formats and flag for SLA support level for each |
Whether file format is accepted, preservation SLA for each accepted format; Also any requirements for quality within format (e.g. compliance with TIFF 6.0 acceptance specs) |
|
|
|
A5.1 |
Consistency rule - check that deposit agreement exists |
Deposit agreement for storage of data specifying access, replicas, consistency checks |
If repository manages, preserves, and/or provides access to digital materials on behalf of another organization, it has and maintains appropriate contracts or deposit agreements. |
|
|
|
B2.1 |
Consistency rule that AIP definition exists |
Statement of characteristics of each AIP |
Repository has an identifiable, written definition for each AIP or class of information preserved by the repository |
|
|
|
B2.2 |
Consistency rule - check allowed transformative migration is performed |
Criteria for allowed transformative migrations |
Repository has a definition of each AIP (or class) that is adequate to fit long-term preservation needs |
|
|
|
B3.9 |
Set / Update descriptive metadata: Consistency check for changes to allowed transformative migrations |
Procedure for updating transformative migration strategy: Audit trail of changes; Consistency check for changes to migration strategy |
Repository has mechanisms to change its preservation plans as a result of its monitoring activities |
|
|
|
B4.2 |
Consistency rule - check required metadata |
Validation that minimum descriptive metadata is present |
Repository captures or creates minimum descriptive metadata and ensures that it is associated with the AIP |
The full assessment of the TDR criteria takes 13 pages to print in 8-point type. The complete mapping is available upon request. Please contact Reagan Moore at [email protected] for a copy or visit the PLEDGE project website [http://pledge.mit.edu].
5. TRUSTED DIGITAL REPOSITORY
The automation of the verification of the assessment criteria for a trusted digital repository can now be implemented as a set of periodic rules that are applied to the preservation environment. The rules examine the persistent state information, compare the values with the desired values, and generate reports of the records or properties that are not in compliance. Some of the rules are applied on each operation performed within the preservation environment. Examples are the authentication of the identity of the archivist and the checking of access controls.
Some of the rules are applied as deferred consistency checks. Since preservation environments may be distributed across multiple administrative domains and access multiple types of storage systems, a mechanism is needed to handle wide-area-network failures. If a preservation operation is supposed to create a replica at a remote storage location (to avoid data loss in case of a natural disaster), it may not be possible to complete the operation. The network may be down or the remote storage system may be off line for maintenance. In this case, a deferred consistency flag is set that indicates the replica must still be created. Deferred consistency checks look for such cases and attempt to complete the operation. If the replica is created successfully, the deferred replica creation flag is reset. If the attempt is unsuccessful, the flag is not updated, and a future attempt may succeed in creating the replica.
Consistency rules are typically applied periodically because the preservation environment is a dynamic entity. Properties that have been asserted as verified in the past may change based on circumstances not under the control of the archivist.
To make this concept clearer, consider a validation of integrity. One of the properties should be the existence of replicas at a remote site that have been verified as being bit-for-bit identical with the original. There are multiple sources of risk that can cause this property to become invalid:
- Media corruption - the tape on which the replica was created may be damaged and become unreadable.
- Administrative error - a systems administrator at the remote site may have erased the file.
- Vendor product error - the remote storage system may have corrupted the data. An example is a micro-code update to a tape drive that is incorrectly performed.
- Replicas must be periodically checked to verify that they are still reliable.
- A trustworthy preservation environment is one in which all assertions on integrity and authenticity have been verified within a specified time period. The verification process must be repeated periodically. Preservation environments are live systems that require constant appraisal and validation.
6. SELF-CONSISTENT PRESERVATION ENVIRONMENTS
Given the ability to characterize assessment criteria as rules that verify preservation attribute values, we can now explore the concepts of completeness and self-consistency for preservation environments. Multiple preservation groups have created lists of preservation metadata that should be associated with a trusted digital repository. An example is the PREMIS preservation metadata list. This defines authenticity and integrity metadata, provenance metadata, and administrative metadata that should be created for each record within a digital repository [12].
For trustworthiness, assessment criteria can be defined to validate the attribute value associated with each PREMIS metadata element. Verification tests could include whether the attribute exists, whether the value lies within the expected range or is included in the expected enumerated list. Each record can be examined and a list generated of all records that are non-compliant. When all records have the required metadata, the system can be considered trustworthy.
Assessment criteria, therefore, should provide consistency checks on all preservation metadata associated with each record. A preservation environment can be considered self-consistent when a management policy exists for each required preservation metadata attribute. In practice, there are multiple preservation attributes that are used to express administrative metadata required to keep the preservation environment running correctly. Thus we need to differentiate between the attributes required to assert preservation properties (integrity and authenticity) and attributes required to monitor the running of the preservation environment (time the last set of assertions were validated).
We also want to assert that a preservation environment is complete. If preservation attributes exist for each management policy, then we have closure. We can map from required preservation attributes to the management policies needed to assess trustworthiness. We can then map from these management policies back to the preservation metadata that are needed to keep the preservation environment running successfully. We will have demonstrated that the system is capable of validating the assessment criteria.
This analysis raises the question:
Should preservation environments be based on the management policies required to assert trustworthiness?
Or should preservation environments be defined by a set of required preservation metadata attributes?
In practice, most preservation environments have been designed to associate required preservation metadata with each record. These attributes may then be organized, as in the Life Cycle Data Requirements Guide [13]. A preservation environment that meets these metadata requirements can be defined and implemented.
By examining the preservation environment from the perspective of assessment criteria, we discover that additional preservation metadata are required, associated with all six logical namespaces used to identify resources, persons, records, rules, micro-services, and persistent state information. Examples of these additional preservation attributes include:
- User namespace metadata
-
- Identification as archivist, or staff
- Allowed roles for creating disposition documents, transferring records, annotating records
- Resource namespace metadata
-
- Type of storage system
- Access classification
- Media type
- Rule namespace metadata
-
- Rule type
- Access control
- Version number
- Persistent state namespace metadata
-
- Version number
- Attribute creation date
These additional attributes are needed because the preservation environment itself evolves. Given that the technology that is used to implement a preservation environment changes over time as new technology is acquired, the preservation environment must also evolve to maintain an unchanging record collection. The preservation attributes that are needed to maintain trustworthiness include not only the required preservation attributes associated with the record provenance, but also the preservation attributes that define the preservation environment attributes.
7. SUMMARY
For digital archives and preservation environments to scale up efficiently, and with minimal human intervention, automation of context-specific, well-defined data management policies, their automated enforcement and auditing will be required. This article described the San Diego Supercomputer Center’s development of the iRODS rules-based system for automating data management and preservation operations, and attributes for auditing those operations. An ongoing collaboration between SDSC and MIT used the DSpace digital archiving system to define a set of local policies over existing digital collections and test their interoperability with iRODS to enforce example policies. The iRODS architecture was described in detail, as well as the categories of rules and attributes needed to maintain a preservation environment and audit it over time. Examples of these rules were provided, and observations and analysis of the RLG TDR in light of this work were described. Future work will refine the local policies and their exchange with iRODS (e.g. updating the policies and associated iRODS rules to use the newly publish RLG TRAC [14]) as well as testing the iRODS rules enforcement and auditing procedures using DSpace-defined collection management policies.
8. ACKNOWLEDGMENTS
This project was supported by the National Archives and Records Administration under NSF cooperative agreement 0523307 through a supplement to SCI 0438741, "Cyberinfrastructure; From Vision to Reality". The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the National Science Foundation, the National Archives and Records Administration, or the U.S. government.
9. REFERENCES
1. Audit Checklist for Certifying Digital Repositories, http://www.rlg.org/en/page.php?Page_ID=20769
2. For a general discussion of the definition of authenticity and integrity in digital preservation environments see Lynch, C. (2000). Authenticity and integrity in the digital environment: An exploratory analysis of the central role of trust. In Authenticity in a digital environment (Council on Library and Information Resources report). http://www.clir.org/pubs/reports/pub92/lynch.html
3. DSpace digital repository, http://www.dspace.org/
4. Storage Resource Broker data grid, http://www.sdsc.edu/srb/index.php/Main_Page
5. Moore, R., A. Rajasekar, M. Wan, "Data Grids, Digital Libraries and Persistent Archives: An Integrated Approach to Publishing, Sharing and Archiving Data", Special Issue of the Proceedings of the IEEE on Grid Computing, Vol. 93, No.3, pp. 578-588, March 2005.
6. Rajasekar, A., M. Wan, R. Moore, W. Schroeder, "A Prototype Rule-based Distributed Data Management System", HPDC workshop on "Next Generation Distributed Data Management", May 2006, Paris, France. For more information about iRODS see the website at http://irods.sdsc.edu/
7. The Resource Description Framework (RDF) is a W3C standard http://www.w3.org/RDF/ for a data model to encode structured metadata, including a mechanism to express metadata semantics. RDF data can be expressed in a standard XML schema http://www.w3.org/TR/rdf-syntax-grammar/
8. The Open Archives Information System (OAIS) is a widely-adopted reference model for the components and data structures necessary for an archival, preservation environment. As of March, 2007 the standard can be located at http://public.ccsds.org/publications/archive/650x0b1.pdf
9. METS is an XML schema for modeling complex, structured digital objects that is often used to represent OAIS information packages. The METS DIP profile described for this project will be registered shortly with the METS registration agency (currently the Library of Congress) http://www.loc.gov/standards/mets/
10. Moore, R., "Building Preservation Environments with Data Grid Technology", American Archivist, vol. 69, no. 1, pp. 139-158, July 2006.
11. Moore, R., R. Marciano, "Technologies for Preservation", chapter 6 in "Managing Electronic Records", edited by Julie McLeod and Catherine Hare, Facet Publishing, UK, October 2005.
12. Preservation Metadata: Implementation Strategies (PREMIS) defines a metadata schema to support digital preservation activities and digital lifecycle management. The current schema can be found at http://www.oclc.org/research/projects/pmwg/
13. LCDRG http://www.archives.gov/research/arc/lifecycle-data-requirements.doc
14. The RLG Trusted Repository Audit Checklist (TRAC) was released in March, 2007 is available from http://www.crl.edu/PDF/trac.pdf
10. NOTES
1. As an example, take an assertion about replication for preservation purposes. The control parameter might be " three copies located in different continents ", and the attributes would be the date and location of each copy made.